A detailed study about the file system commands in Unix

- Directories
- Changing directory-cd
- 1.4 The shell
- Filename shorthand
- Input-output redirection
- Pipes
- Processes
- Tailoring the environment
- The rest of the UNIX system
- History and bibliographic notes
The system distinguishes your file called junk from anyone else's of the same name. Below is a complete list of of the file system commands. It is important to learn the commands in order to complete an assignment based on UNIX. Students do not have complete understanding of the commands and seek for help with programming assignments. Go through the blog to understand UNIX better.
Directories
The system distinguishes your file called junk from anyone else's of the same name. The distinction is made by grouping files into directories, rather in the way that books are placed on shelves in a library, so files in different directories can have the same name without any conflict. Generally each user has a personal or home directory, sometimes called login directory, that contains only the files that belong to him or her. When you log in, you are "in" your home directory. You may change the directory -you are working in often called your working or current directory but your home directory is always the same. Unless you take special action, when you create a new file it is made in your current directory. Since this is initially your home directory, the file is unrelated to a file of the same name that might exist in someone else's directory.
A directory can contain other directories as well as ordinary files ("Great directories have lesser directories..."). The natural way to picture this organi zation is as a tree of directories and files. It is possible to move around within this tree, and to find any file in the system by starting at the root of the tree and moving along the proper branches. Conversely, you can start where you are and move toward the root.
Let's try the latter first. Our basic tool is the command pwd ("print work ing directory"), which prints the name of the directory you are currently in:
Table 1 . 1 : Common Files System Commands
| Is | list names of all files in current directory |
| Is filenames | list only the named file |
| Is -t | list in time order, most recent first |
| Is -1 | list long : more imformation; also Is – It |
| Is -u | list by time last used; also Is – Iu , Is – Iut |
| Is -r | list in reverse order; also –rt, - rIt, etc |
| ed filename | edit named file |
| cp file1 file2 | copy file1 to file2, overwrite old file2 if it exists |
| mv file1 file2 | move file1 to file2, overwrite old file2 if it exists |
| rm filename | removed named files, irrevocably |
| cat filename | print content of named file |
| pr filename | print contents with header, 66 line per page |
| pr -n filename | print in n colums |
| pr -m filename | print named files side by side (multiple colums) |
| wc filename | count lines , wprds and characters for each file |
| wc -1 filename | count lines for each file |
| grep pattern filename | print lines matching pattern |
| grep -v pattern files | print lines not matching pattern |
| sort filename | sort files alphabetically by line |
| tail filename | print last 10 lines of file |
| tail -n filename | print last n lines of file |
| tail +n filename | start printing file at line n |
| cmp file1 file2 | print location of first difference |
| diff file1 file2 | print all difference between files |
$ pwd
/usr/you
$
(0, 0, 0); font-size: 0.875rem; text-align: center;">This says that you are currently in the directory you, in the directory usr. which in turn is in the root directory, which is conventionally called just "/". The characters separate the components of the name; the limit of 14 characters mentioned above applies to each component of such a name. On many systems, /uar is a directory that contains the directories of all the normal users of the system. (Even if your home directory is not /usr/you, pwd will print something analogous, so you should be able to follow what happens below.)
you should get exactly the same list of file names as you get from a plain Is. When no arguments are provided, 1s lists the contents of the current direc tory: given the name of a directory, it lists the contents of that directory. Next, try
$ Is/usr
This should print a long series of names, among which is your own login direc tory you.
The next step is to try listing the root itself. You should get a response similar to this:
$ Is /
bin boot
dev
etc
lib
tmp
unix
usr
$
(Don't be confused by the two meanings of : it's both the name of the root and a separator in filenames.) Most of these are directories, but unix is actu ally a file containing the executable form of the UNIX kernel. More on this in Chapter 2.
Now try
$ cat /usr/you/junk
(if junk is still in your directory). The name
/usr/you/junk
is called the pathname of the file. "Pathname" has an intuitive meaning: it represents the full name of the path from the root through the tree of directories to a particular file. It is a universal rule in the UNIX system that wher ever you can use an ordinary filename, you can use a pathname. The file system is structured like a genealogical tree; here is a picture that may make it clearer
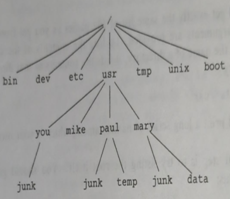
Almost all of the commands we have talked about so far fit this model; the only exceptions are commands like date and who that read no input, and a few like emp and diff that have a fixed number of file inputs. (But look at the option on these.) Your file named Junk is unrelated to Paul's or to Mary's. Pathnames aren't too exciting if all the files of interest are in your own directory, but if you work with someone else or on several projects con currently, they become handy indeed. For example, your friends can print your junk by saying
$ cat /usr/you/junk
Similarly, you can find out what files Mary has by saying
$ Is /usr/mary
data
Junk
$
or make your own copy of one of her files by $ cp /usr/mary/data data
$ cp /usr/mary/data data
edit her file:
ed /usr/mary/data
If Mary doesn't want you poking around in her files, or vice versa, privacy can be arranged. Each file and directory has read-write-execute permissions for the owner, a group, and everyone else, which can be used to control access. (Recall 18-1.) In our local systems, most users most of the time find open ness of more benefit than privacy, but policy may be different on your system, so we'll get back to this in Chapter 2.
As a final set of experiments with pathnames, try
$ ls /bin/usr/bin
Do some of the names look familiar? When you run a command by typing its name after the prompt, the system looks for a file of that name. It normally looks first in your current directory (where it probably doesn't find it), then in /bin, and finally in /usr/bin. There is nothing special about commands like cat or Is, except that they have been collected into a couple of direc tories to be easy to find and administer. To verify this, try to execute some of these programs by using their full pathnames:
$/bin/date
Mon Sep 26 23:29:32 EDT 1983
$/bin/who
Srm tty1 Sep 26 22:20
Cvw tty4 Sep 26 22:40
You tty5 Sep 26 23:04
Exercise 1-3. Try
Is/usr/games
and do whatever comes naturally. Things might be more fun outside of normal working hours.
Changing directory-cd
If you work regularly with Mary on information in her directory, you can say "I want to work on Mary's files instead of my own." This is done by changing your current directory with the cd command:
$ cd /usr/mary
Now when you use a filename (without /'s) as an argument to cat or pr, it refers to the file in Mary's directory. Changing directories doesn't affect any permissions associated with a file. if you couldn't access a file from your own directory, changing to another directory won't alter that fact. It is usually convenient to arrange your own files so that all the files related to one thing are in a directory separate from other projects. For example, you want to write a book, you might want to keep all the text in a directory called book. The command mkdir makes a new directory.
$ mkdir book Make a directory
$ cd book Go to it
$ pwd Make sure you're in the right place
/usr/you/book
… Write the book (several minutes pass)
$ cd .. Move up one level in file system
$ pwd
/usr/you
$
‘..’ refers to the parent of whatever directory you are currently in, the direc tory one level closer to the root. . is a synonym for the current directory.
$ cd Return to home directory
all by itself will take you back to your home directory, the directory where you log in. Once your book is published, you can clean up the files. To remove the directory book, remove all the files in it (we'll show a fast way shortly), then ed to the parent directory of book and type
$ rmdir book
rmdir will only remove an empty directory.
1.4 The shell
When the system prints the prompt $ and you type commands that get exe cuted, it's not the kernel that is talking to you, but a go-between called the command interpreter or shell. The shell is just an ordinary program like date or who, although it can ¿ some remarkable things. The fact that the shell sits.
between you and the facilities of the kernel has real benefits, some of which we'll talk about here. There are three main ones:
- Filename shorthands: you can pick up a whole set of filenames as arguments to a program by specifying a pattern for the names the shell will find the filenames that match your pattern.
- Input-output redirection: you can arrange for the output of any program to go into a file instead of onto the terminal, and for the input to come from a file instead of the terminal. Input and output can even be connected to other programs.
- Personalizing the environment: you can define your own commands and shorthands.
Filename shorthand
Let's begin with filename patterns. Suppose you're typing a large document like a book. Logically this divides into many small pieces, like chapters and perhaps sections. Physically it should be divided too, because it is cumbersome to edit large files. Thus you should type the document as a number of files. You might have separate files for each chapter, called ch1, ch2, etc. Or, if each chapter were broken into sections, you might create files called
ch1.1
ch1.2
ch1.3
ch2.1
ch2.2
which is the organization we used for this book. With a systematic naming convention, you can tell at a glance where a particular file fits into the whole. What if you want to print the whole book? You could say
$pr ch1.1 ch.2 ch1.3....
but you would soon get bored typing filenames and start to make mistakes. This is where filename shorthand comes in. If you say
$ pr ch*
the shell takes the to mean "any string of characters," so che is a pattern that matches all filenames in the current directory that begin with ch. The shell creates the list, in alphabeticalt order, and passes the list to pr. The pr command never sees the ; the pattern match that the shell does in the current directory generates a list of strings that are passed to pr.
The crucial point is that filename shorthand is not a property of the pr command, but a service of the shell. Thus you can use it to generate a sequence of filenames for any command. For example, to count the words in the first chapter:
$ wce ch1.
113 562 3200 ch1.0
935 4081 22435 ch1.1
974 4191 22756 ch1.2
378 1561 8481 ch1.3
1293 5298 28841 ch1.4
33 194 1190 ch1.5
75 323 2030 ch1.6
3801 16210 88933 total
$
There is a program called echo that is especially valuable for experiment ing with the meaning of the shorthand characters. As you might guess, echo does nothing more than echo its arguments:
$ echo hello world
hello world
$
But the arguments can be generated by pattern-matching:
$ echo ch1. *
lists the names of all the files in Chapter 1.
$ echo *
lists all the filenames in the current directory in alphabetical order,
$ pr *
prints all your files (in alphabetical order), and
$ rm *
removes all files in your current directory. (You had better be very sure that's what you wanted to say!) The * is not limited to the last position in a filename's can be any where and can occur several times. Thus
$ rm * . save
removes all files that end with .save. Notice that the filenames are sorted alphabetically, which is not the same as numerically. If your book has ten chapters, the order might not be what you intended, since ch 10 comes before ch2:
$ echo.
ch1.1 ch1.2 ch10.1 ch10.2. ch2.1 ch2.2 ….
The is not the only pattern-matching feature provided by the shell, although it's by far the most frequently used. The pattern [...] matches any of the characters inside the brackets. A range of consecutive letters or digits can be abbreviated:
$ pr ch [12346789]* Print chapters 1,2,3,4,6,7,8,9 but not 5
$ pr ch[1-46-9]* Same thing
$ rm temp[a-z] Remove any of tempa,.., tempz that exists
The ? pattern matches any single character:
$ Is ? List files with single-character names
$ Is -1 ch?. 1 List ch1.1 ch2.1 ch3. 1. etc. but not ch10.1
rm temp? Remove files temp1,..., tempa, etc.$ rm temp?
Note that the patterns match only existing filenames. In particular, you cannot make up new filenames by using patterns. For example, if you want to expand ch to chapter in each filename, you cannot do it this way:
$ mv ch.* chapter.* Doesn't work!
because chapter. matches no existing filenames.
Pattern characters like can be used in pathnames as well as simple filenames; the match is done for each component of the path that contains a special character. Thus /usr/mary/ performs the match in /usr/mary. and /usr//calendar generates a list of pathnames of all user calendar files.
If you should ever have to turn off the special meaning of *, ?, etc... enclose the entire argument in single quotes, as in
$ Is ‘ ? ’
You can also precede a special character with a backslash:
(Remember that because ? is not the erase or line kill character, this backslash is interpreted by the shell, not by the kernel.) Quoting is treated at length in Chapter 3.
Exercise 1-4. What are the differences among these commands?
$ Is junk $ echo junk
$ / $ echo/
$ Is $ echo
$ Is * $ echo*
$ Is ‘ * ‘ $ echo ‘ * ‘
Input-output redirection
Most of the commands we have seen so far produce output on the terminal; some, like the editor, also take their input from the terminal. It is nearly universal that the terminal can be replaced by a file for either or both of input and output. As one example,
$ Is
makes a list of filenames on your terminal, But if you say
$ is >filelist
that same list of filenames will be placed in the file filelist instead. The symbo!> means "put the output in the following file, rather than on the termi nal." The file will be created if it doesn't already exist, or the previous con tents overwritten. if it does. Nothing is produced on your terminal. As another example, you can combine several files into one by capturing the out put of cat in a file:
$ cat f1 f2 £3 >temp
The symbol >> operates much as > does, except that it means "add to the end of." That is,
$ cat f1 f2 f3 >>temp
copies the contents of £1, £2 and £3 onto the end of whatever is already in instead of overwriting the existing contents. As with, if temp doesn't exist, it will be created initially empty for you. In a similar way, the symbol < means to take the input for a program from the following file, instead of from the terminal. Thus, you can prepare a letter in file let, then send it to several people with
$ mail mary joe tom bob
In all of these examples, blanks are optional on either side of> or <, but our formatting is traditional.
Given the capability of redirecting output with, it becomes possible to combine commands to achieve effects not possible otherwise. For example, to print an alphabetical list of users.
$ who >teap
$ sort >temp
Since who prints one line of output per logged-on user, and we -1 counts lines (suppressing the word and character counts), you can count users with
$ who >temp
$ wc-1 >temp
You can count the files in the current directory with
$2 >temp
$ wc -1
though this includes the filename temp itself in the count. You can print the filenames in three columns with
$ is >temp
$ pr -3
And you can see if a particular user is logged on by combining who and grep:
$ who >temp
$ grep mary
In all of these examples, as with filename pattern characters like, it's important to remember that the interpretation of > and < is being done by the shell, not by the individual programs. Centralizing the facility in the shell means that input and output redirection can be used with any program; the program itself isn't aware that something unusual has happened. This brings up an important convention. The command
$ sort
sorts the contents of the file temp, as does
$ sort temp
but there is a difference. Because the string
$ sort temp1 temp2 temp3
but if no filenames are given, it sorts its standard input. This is an essential property of most commands: if no filenames are specified, the standard input is processed. This means that you can simply type at commands to see how they work.
For example.
$ sort
ghi
abc
def
ctl – d
abc
def
ghi
$
In the next section, we will see how this principle is exploited.
Exercise 1-5. Explain why
$ Is >Is . out
causes in. out to be included in the list of names.
Exercise 1-6. Explain the output from
$ wc temp >temp
If you misspell a command name, as in
$ woh >temp
what happens?
Pipes
All of the examples at the end of the previous section rely on the same trick: putting the output of one program into the input of another via a tem porary file. But the temporary file has no other purpose; indeed, it's clumsy to have to use such a file. This observation leads to one of the fundamental con tributions of the UNIX system, the idea of a pipe. A pipe is a way to connect the output of one program to the input of another program without any tem porary file; a pipeline is a connection of two or more programs through pipes. Let us revise some of the earlier examples to use pipes instead of temporaries. The vertical bar character tells the shell to set up a pipeline:
$ who | sort Print sorted list of users
$ who| wc -1 Count users
$ Is | wc -1 Count files
$ is | pr -3 3-column list of filenames
$ who | grep mary Look for particular user
Any program that reads from the terminal can read from a pipe instead: any program that writes on the terminal can write to a pipe. This is where the convention of reading the standard input when no files are named pays off: any program that adheres to the convention can be used in pipelines. grep, pr.
sort and we are all used that way in the pipelines above.. You can have as many programs in a pipeline as you wish:
$ Is | pr -3 | 1pr
creates a 3-column list of filenames on the line printer, and
$ who | grep mary | wc -1
counts how many times Mary is logged in.
The programs in a pipeline actually run at the same time, not one after another. This means that the programs in a pipeline can be interactive; the kernel looks after whatever scheduling and synchronization is needed to make it all work.
As you probably suspect by now, the shell arranges things when you ask for a pipe; the individual programs are oblivious to the redirection. Of course, programs have to operate sensibly if they are to be combined this way. Most commands follow a common design, so they will fit properly into pipelines at any position. Normally a command invocation looks like
command optional-arguments optional-filenames
If no filenames are given, the command reads its standard input, which is by default the terminal (handy for experimenting) but which can be redirected to come from a file or a pipe. At the same time, on the output side, most com mands write their output on the standard output, which is by default sent to the terminal. But it too can be redirected to a file or a pipe.
Error messages from commands have to be handled differently, however, or they might disappear into a file or down a pipe. So each command has a standard error output as well, which is normally directed to your terminal.Or, as a picture:

Almost all of the commands we have talked about so far fit this model; the only exceptions are commands like date and who that read no input, and a few like emp and diff that have a fixed number of file inputs. (But look at the option on these.)
Exercise 1-7. Explain the difference between
$ who | sort
And
$ who >sort
Processes
The shell does quite a few things besides setting up pipes. Let us turn briefly to the basics of running more than one program at a time, since we have already seen a bit of that with pipes. For example, you can run two pro grams with one command line by separating the commands with a semicolon: the shell recognizes the semicolon and breaks the line into two commands:
$ date; who
Tue Sep 27 01:03:17 EDT 1983
Ken tty0 Sep 27 00:43
Dmr tty1 Sep 26 23:45
Rob tty2 Sep 26 23:59
Bwk tty3 Sep 27 00:06
Jj tty4 Sep 26 23:31
You tty5 Sep 26 23:04
Ber tty7 Sep 26 23:34
$
Both commands are executed (in sequence) before the shell returns with a prompt character.
You can also have more than one program running simultaneously if you wish. For example, suppose you want to do something time-consuming like counting the words in your book, but you don't want to wait for we to finish before you start something else. Then you can say
$ wc ch *>wc .out &
6944 Process-id printed by the shell
$
The ampersand & at the end of a command line says to the shell "start this command running, then take further commands from the terminal immedi ately," that is, don't wait for it to complete. Thus the command will begin. but you can do something else while it's running. Directing the output into the file wc.out keeps it from interfering with whatever you're doing at the same time.
An instance of a running program is called a process. The number printed by the shell for a command initiated with & is called the process-id; you can use it in other commands to refer to a specific running program.
It's important to distinguish between programs and processes. we is a program; each time you run the program we, that creates a new process. If several instances of the same program are running at the same time, each is a separate process with a different process-id. If a pipeline is initiated with &, as in
$ pr ch*| 1pr &
6951 Process-id of 1pr
the processes in it are all started at once-the & applies to the whole pipeline. Only one process-id is printed, however, for the last process in the sequence.
The command
$ wait
waits until all processes initiated with & have finished. If it doesn't return immediately, you have commands still running. You can interrupt wait with DELETE
You can use the process-id printed by the shell to stop a process initiated
$ kill 6944
If you forget the process-id, you can use the command pa to tell you about everything you have running. If you are desperate, kill 0 will kill all your processes except your login shell. And if you're curious about what other users are doing. ps -ag will tell you about all processes that are currently running. Here is some sample output:
$ ps -ag
PID TTY TIME CMD
36 co 6:29 /etc/cron
6423 5 0:02 -sh
6704 1 0:04 -sh
6722 1 0:12 vi paper
4430 2 0:03 -sh
6612 7 0:03 -sh
6628 7 1:13 rogue
6843 2 0:02 write dmr
6949 4 0:01 login bimmler
6952 5 0:08 pr ch1.1 ch1.2 ch1.3 ch1.4
6951 5 0:03 1pr
6959 5 0:02 pm -ag
6844 1 0:02 write rob
PID is the process-id; TTY is the terminal associated with the process (as in who); TIME is the processor time used in minutes and seconds; and the rest is the command being run. pa is one of those commands that is different on dif ferent versions of the system, so your output may not be formatted like this. Even the arguments may be different see the manual page ps(1).
Processes have the same sort of hierarchical structure that files do: each process has a parent, and may well have children. Your shell was created by a process associated with whatever terminal line connects you to the system. As you run commands, those processes are the direct children of your shell. If you
run a program from within one of those, for example with the command to escape from ed, that creates its own child process which is thus a grandchild of the shell.
Sometimes a process takes so long that you would like to start it running. then turn off the terminal and go home without waiting for it to finish. But if you turn off your terminal or break your connection, the process will normally be killed even if you used &. The command nohup ("no hangup") was created to deal with this situation: if you say
$ nohup command &
the command will continue to run if you log out. Any output from the command is saved in a file called nohup.out. There is no way to nohup a com mand retroactively. If your process will take a lot of processor resources, it is kind to those who share your system to run your job with lower than normal priority; this is done by another program called nice:
$ nice expensive-command &
nohup automatically calls nice, because if you're going to log out you can afford to have the command take a little longer. Finally, you can simply tell the system to start your process at some wee hour of the morning when normal people are asleep, not computing. The com mand is called at(1):
$ at time
whatever commands
you want…
ctl-d
$
This is the typical usage, but of course the commands could come from a file:
$ at 3am
$
Times can be written in 24-hour style like 2130, or 12-hour style like 930pm.
Tailoring the environment
One of the virtues of the UNIX system is that there are several ways to bring it closer to your personal taste or the conventions of your local computing environment. For example, we mentioned earlier the problem of different standards for the erase and line kill characters, which by default are usually # and @. You can change these any time you want with
$ stty erase e kill k
where e is whatever character you want for erase and k is for line kill. But it's a brother to have to type this every time you log in.
color: rgb(0, 0, 0);">The shell comes to the rescue. If there is a file named profile in your logie directory, the shell will execute the commands in it when you log in, before printing the first prompt. So you can put commands into profile to set up your environment as you like it, and they will be executed every time you log in.
The first thing most people put in their profile is
Stty erase <-
We're using here so you can see it, but you could put a literal backspace in your profile. etty also understands the notation "x for cl-x, so you can get the same effect with
stty erase ‘^h’
because cl-h is backspace. (The character is an obsolete synonym for the pipe operator 1, so you must protect it with quotes.) If your terminal doesn't have sensible tab stops, you can add -tabs to the stty line:
stty erase ‘^h' -tabs
If you like to see how busy the system is when you log in, add
who | wc -1
to count the users. If there's a news service, you can add news. Some people like a fortune cookie:
/usr/games/fortune
After a while you may decide that it is taking too long to log in, and cut your profile back to the bare necessities.
Some of the properties of the shell are actually controlled by so-called shell variables, with values that you can access and set yourself. For example, the prompt string, which we have been showing as $, is actually stored in a shell variable called PS1, and you can set it to anything you like, like this:
PS1='Yes dear?
The quotes are necessary since there are spaces in the prompt string. Spaces are not permitted around the in this construction.
The shell also treats the variables HOME and MAIL specially. HOME is the name of your home directory; it is normally set properly without having to be in profile. The variable MAIL names the standard file where your mail is kept. If you define it for the shell, you will be notified after each command if new mail has arrived:
MAIL /usr/spool/mail/you
(The mail file may be different on your system; /usr/mail/you is also com mon.)
Probably the most useful shell variable is the one that controls where the shell looks for commands. Recall that when you type the name of a command. the shell normally looks for it first in the current directory, then in /bin, and then in /usr/bin. This sequence of directories is called the search path, and is stored in a shell variable called PATH. If the default search path isn't what you want, you can change it, again usually in your profile. For example, this line sets the path to the standard one plus /usr/games:
PATH.:/bin:/usr/bin:/usr/games One way...
The syntax is a bit strange: a sequence of directory names separated by colons. Remember that.' is the current directory. You can omit the ; a null com ponent in PATH means the current directory. An alternate way to set PATH in this specific case is simply to augment the previous value:
PATH=$PATH:/usr/games …Another way
You can obtain the value of any shell variable by prefixing its name with a 5. In the example above, the expression $PATH retrieves the current value, to which the new part is added, and the result is assigned back to PATH. You can verify this with echo:
$ echo PATH is $PATH
PATH is :/bin:/usr/bin:/usr/games
$ echo $HOME Your login directory
/usr/you
$
If you have some of your own commands, you might want to collect them in a directory of your own and add that to your search path as well. In that case, your PATH might look like this:
PATH=:$HOME/bin:/bin:/usr/bin:/usr/games
We'll talk about writing your own commands in Chapter 3. Another variable, often used by text editors fancier than ed, is TERM, which names the kind of terminal you are using. That information may make it possible for programs to manage your screen more effectively. Thus you might add something like
TERM-adm3
to your profile file.
It is also possible to use variables for abbreviation. If you find yourself fre quently referring to some directory with a long name, it might be worthwhile adding a line like
D=/horribly/long/directory/name
to your profile, so that you can say things like
$ cd $d
Personal variables like d are conventionally spelled in lower case to distinguish them from those used by the shell itself, like PATH. Finally, it's necessary to tell the shell that you intend to use the variables in other programs; this is done with the command export, to which we will return in Chapter 3:
export MAIL PATH TERM
To summarize, here is what a typical .profile file might look like:
$ cat profile
stty erase ‘^h" -tabs
MAIL=/usr/spool/mail/you
PATH= :$HOME/bin:/bin:/usr/bin:/usr/games
TERM-adm3
b=$HOME/book
export MAIL PATH TERM b
date
who| wc -1
We have by no means exhausted the services that the shell provides. One of the most useful is that you can create your own commands by packaging existing commands into a file to be processed by the shell. It is remarkable how much can be achieved by this fundamentally simple mechanism. Our dis cussion of it begins in Chapter 3.
The rest of the UNIX system
There's much more to the UNIX system than we've addressed in this chapter, but then there's much more to this book. By now, you should feel comfortable with the system and, particularly, with the manual. When you have specific questions about when or how to use commands, the manual is the place to look. It is also worth browsing in the manual occasionally, to refresh your knowledge of familiar commands and to discover new ones. The manual describes many programs we won't illustrate, including compilers for languages like FORTRAN 77; calculator programs such as be(1); cu(1) and uucp(1) for inter-machine communication: graphics packages; statistics programs; and eso terica such as units(1).
As we've said before, this book does not replace the manual, it supplements it. In the chapters that follow we will look at pieces and programs of the UNIX system, starting from the information in the
manual but following the threads that connect the components. Although the program interrelationships are never made explicit in the manual, they form the fabric of the UNIX program ming environment.
History and bibliographic notes
The original UNIX paper is by D. M. Ritchie and K. L. Thompson: "The UNIX Time-sharing System," Communications of the ACM, July, 1974, and reprinted in CACM, January, 1983. (Page 89 of the reprint is in the March 1983 issue.) This overview of the system for people interested in operating systems is worth reading by anyone who programs.
The Bell System Technical Journal (BSTJ) special issue on the UNIX system (July, 1978) contains many papers describing subsequent developments, and some retrospective material, including an update of the original CACM paper by Ritchie and Thompson. A second special issue of the BSTJ, containing new UNIX papers, is scheduled to be published in 1984.
"The UNIX Programming Environment," by B. W. Kernighan and J. R. Mashey (IEEE Computer Magazine, April, 1981), attempts to convey the essential features of the system for proprammers.
The UNIX Programmer's Manual, in whatever version is appropriate for your system, lists commands, system routines and interfaces, file formats, and maintenance procedures. You can't live without this for long, although you will probably only need to read parts of Volume 1 until you start programming. Volume 1 of the 7th Edition manual is published by Holt, Rinehart and Winston.
Volume 2 of the UNIX Programmer's Manual is called "Documents for Use with the UNIX Time-sharing System" and contains tutorials and reference manuals for major commands. In particular, it describes document preparation programs and program development tools at some length. You will want to read most of this eventually. A UNIX Primer, by Ann and Nico Lomuto (Prentice-Hall. 1983), is a good introduction for raw beginners, especially non-programmers.